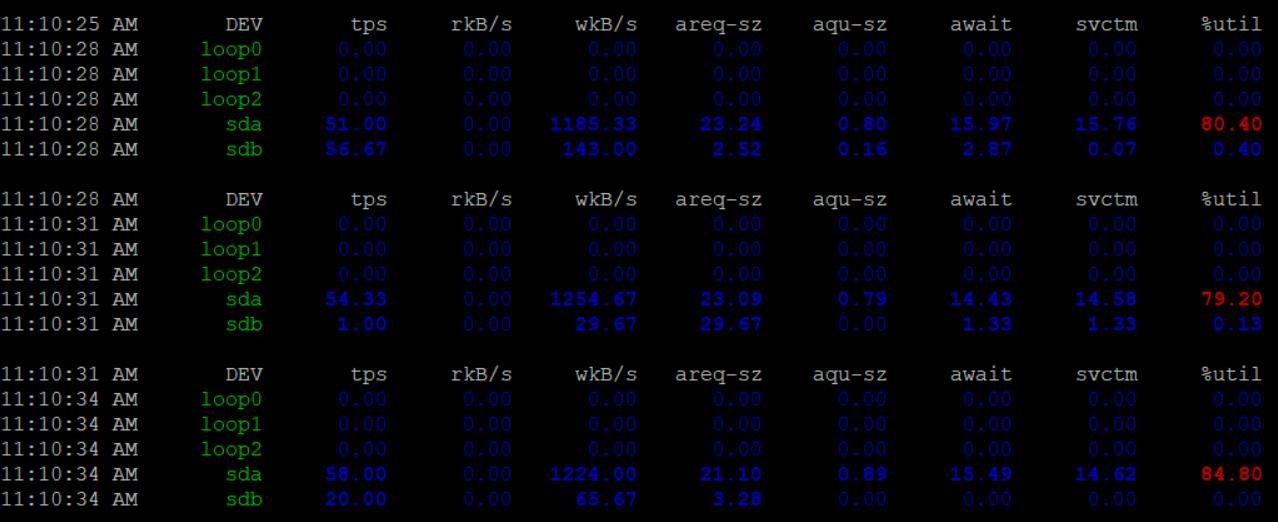
with pd.ExcelWriter(f"xxx.xlsx", engine="openpyxl", date_format="YYYY-MM-DD", datetime_format="YYYY-MM-DD HH:MM:SS" ) as writer: df.to_excel(writer) sheet = writer.sheets["Sheet1"] # 设置列宽 sheet.column_dimensions['A'].width = 12.5 # 设置行高 sheet.row_dimensions[1].height = 72 # 设置表头(第一行)自动换行 r = sheet[1] for c in r: c.alignment = openpyxl.styles.Alignment(wrapText=True) # 设置表体数字格式显示4位小数 for i, r in enumerate(sheet): for j, c in enumerate(r): if i != 0 and j != 0: c.number_format = "0.0000"
// see http://vuejs-templates.github.io/webpack for documentation. var path = require('path')
module.exports = { build: { env: require('./prod.env'), index: path.resolve(__dirname, '../dist/index.html'), assetsRoot: path.resolve(__dirname, '../dist'), assetsSubDirectory: 'static', assetsPublicPath: '/view/', productionSourceMap: true, // Gzip off by default as many popular static hosts such as // Surge or Netlify already gzip all static assets for you. // Before setting to `true`, make sure to: // npm install --save-dev compression-webpack-plugin productionGzip: false, productionGzipExtensions: ['js', 'css'], // Run the build command with an extra argument to // View the bundle analyzer report after build finishes: // `npm run build --report` // Set to `true` or `false` to always turn it on or off bundleAnalyzerReport: process.env.npm_config_report }, dev: { env: require('./dev.env'), port: 8080, autoOpenBrowser: true, assetsSubDirectory: 'static', assetsPublicPath: '/', proxyTable: { '/api': { target: "http://backend-server:30101", // 测试环境下配置端口转发 changeOrigin: true, pathRewrite: { "^/api": "", // 重写路径,去掉前缀api } } }, // CSS Sourcemaps off by default because relative paths are "buggy" // with this option, according to the CSS-Loader README // (https://github.com/webpack/css-loader#sourcemaps) // In our experience, they generally work as expected, // just be aware of this issue when enabling this option. cssSourceMap: false } }